importance of “content” in SEO
Jan 2, 2013 00:00 · 890 words · 5 minute read
Creating unique and fresh content for users with relevant information helps Google to reach its goal, which is “give people the most relevant answers to their queries as quickly as possible” (Singhal & Cutts, Finding more high-quality sites in search, 2011).
Therefore, useful content is one of the most important signals that Google considers in its ranking algorithm. Users like good content and usually share them with others via social media, forums and email services.
Google uses its “Panda” algorithm to evaluate the quality of the content. It uses various criteria in its evaluation such as checking the similarity of the content, amount of stylistic or factual errors, attractiveness of the topic for the visitors, originality of the information, rationality of the article, comprehensiveness of the article and amount of ads that is used inside the article (Singhal, More guidance on building high-quality sites, 2011).
In addition, Google pay more attention to the page content in comparison with headers and menu to choose relevant text for its snippets (Cutts, Ten recent algorithm changes, 2011).
Google ask webmasters to write their unique and exclusive content according to the words that users might search as they might use different keywords to search according to their knowledge about the topic.
Although spelling and grammar mistake is not included in Google’s signals yet, Google recommends webmasters to avoid writing large sloppy text which does not have proper subheading and paragraph and are not easy-to-read (GoogleWebmasterHelp, Do spelling and grammar matter when evaluating content and site quality?, 2011).
Recently, Google cares more about the freshness of the content by using its Caffeine web indexing system which allows it to crawl and index the web continuously on a giant scale (Grimes, 2010) (Singhal, Giving you fresher, more recent search results, 2011).
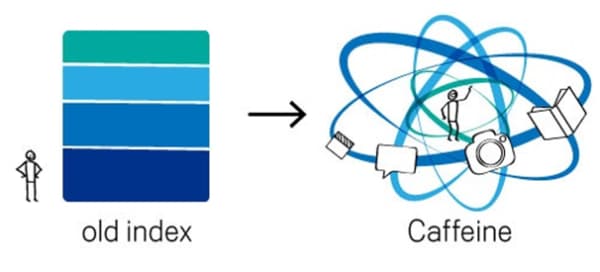
|
|---|
| Figure 15: Google caffeine index vs old system (Grimes, 2010) |
Google claims that different queries need different freshness and its new algorithm ensure users that they get most recent answers according to the level of freshness that their query requires. For instance users keen to know about the latest information that is available on the web for the recent “hot topics”, “annual events” or even the information which is subject to change often. However, there are too many old results that might be still useful for users such as “food recipes” (Singhal, Giving you fresher, more recent search results, 2011).
On the other hand, Google penalised the websites which tried to manipulate search engine by putting unnecessary keywords in their content or using duplicate or copyright content at their end (Raman, 2006) (Google, Search Engine Optimization starter guide, 2010).
Duplicate content refers to the use of block contents across one or more domains that are almost similar together. For example, store items with multiple URLs, printer-only version of a page, or even forums that generate both stripped-down and regular pages. Google recommend webmaster that instead of blocking these duplicate contents with “robots.txt” file try to use “301s” and redirect mirror version to their preferred URL. Also it can be helpful to have different top-level domain to handle multi-regional and multi-language websites but if a website serve the same content on different URL (e.g. example.us/ and example.com/us/) it is more useful to use “rel=canonical” link element to point to its preferred URL, in order to avoid getting penalised by Google (Google, Multi-regional and multilingual sites, 2011).
At the same point, websites should minimise their similar content, empty pages by understanding their content management system properly and also use URL parameter tool to avoid having the pages that do not change with parameters such as “sessionId”, “affiliatedId”, “brandId” and so on. It can help Google to understand the purpose of each parameter and know how to handle them properly (Google, Duplicate content, 2011) (Google, URL parameters, 2011).
Although Google suggests webmasters to use “Canonical” link tag to help its crawlers find out the preferred version of the several pages which have highly similar content, it is not guaranteed that Google will follow it in all cases as it may point to an infinitive loop unintentionally. (Mueller, Handling legitimate cross-domain content duplication, 2009) (Google, About rel=”canonical”, 2011) (Google, Canonicalization, 2011).
References
- Singhal, A. (2011). Giving you fresher, more recent search results. Retrieved January 7, 2012, from Google blog: [link]
- Singhal, A., & Cutts, M. (2011). Finding more high-quality sites in search. Retrieved January 7, 2012, from google blog: [link]
- Mueller, J. (2009). Handling legitimate cross-domain content duplication. Retrieved January 7, 2012, from google webmaster central blog: [link]
- Raman. (2006). Finding easy-to-read web content. Retrieved January 7, 2012, from google blog: [link]
- Google. (2011). Canonicalization. Retrieved January 7, 2012, from Google Webmaster Tools Help: [link]
- Google. (2011). About rel=”canonical”. Retrieved January 7, 2012, from Google Webmaster Tools Help : [link]
- Google. (2011). URL parameters. Retrieved January 7, 2012, from Google Webmaster Tools Help: [link]
- Google. (2011). Duplicate content. Retrieved January 7, 2012, from Google Webmaster Tools Help: [link]
- Google. (2011). Multi-regional and multilingual sites. Retrieved January 7, 2012, from Webmaster Tools Help: [link]
- Grimes, C. (2010). Our new search index: Caffeine. Retrieved January 7, 2012, from google blog: [link]
- GoogleWebmasterHelp. (2011). Do spelling and grammar matter when evaluating content and site quality? Retrieved January 7, 2012, from Youtube: [link]
- Cutts, M. (2011). Ten recent algorithm changes. Retrieved January 7, 2012, from inside search, The official Google search blog: [link]